728x90
어제 회의를 통해 무엇을 할 지 정확하게 정했고, 각자 맡은 부분에서 필요한 컬럼과 과제가 컬럼 30개였으니 추가적으로 넣을 컬럼을 고른 다음에서야 데이터를 뽑기 시작해서 데이터를 뽑는 것으로 끝났다.
각자 티어를 맡아 데이터를 받아오고, 나중에 받아온 데이터들을 cvs 파일로 공유하기로 해서 나는 내 노트북으로는 다이아, 학원에서 내 자리의 컴퓨터로는 브론즈를 받아오기로 했는데 노는 api키가 없어서 브론즈는 오늘 학원에 가서 급하게 조금 받아왔다. (그래서 다이아는 전처리 없이 10만 데이터인데 브론즈는 전처리 없이 3만 데이터였다..내일 마무리 작업 전에 브론즈는 조금 더 받아와야겠다.)
내가 맡은 부분:
데이터 티어: 다이아 / 브론즈
시각 데이터: 닉네임 길이 별 승률 / 퍼블이 가장 많이 나오는 라인
(추가적으로 팀원이랑 PPT 작업도 같이 했다.)
1. 연습용: 다이아로만 시각화 해보기
1-0) 시작 전
더보기
import my_utils as mu
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import seaborn as sns
from matplotlib.gridspec import GridSpec- import
font_path = "C:/Windows/Fonts/gulim.ttc"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font) # 윈도우- 차트에 한글로 작성 시 깨지지 않게 하기 위한 설정
conn = mu.connect_mysql()
query = 'select * from lol_datas where tier="DIAMOND"'
df = pd.DataFrame(mu.sql_execute_dict(conn,query))
conn.close()- DB에 넣어둔 데이터를 불러와 데이터 프레임으로 저장
1-1) 닉네임 길이 별 승률
더보기

가린 부분은 유저들 닉네임이다.
oow = 승률
tnw_df = df[['tier','summonerName','win']]
tnw_df = pd.DataFrame(tnw_df[tnw_df.summonerName.str.len()!=0])
tnw_df['sNameLen'] = tnw_df['summonerName'].str.len()
tnw_df['cnt'] = 1
tnw_df = tnw_df[['tier','summonerName','sNameLen','win','cnt']]
tnw_df['win'] = tnw_df.apply(lambda x: 1 if x.win=='True' else 0,axis=1)
tnw_df2 = tnw_df[['sNameLen','win','cnt']].groupby(['sNameLen']).sum()
tnw_df2['oow'] = round((tnw_df2['win']/tnw_df2['cnt'])*100,2)list_x = [3,4,5,6,7,8,9,10,11,12,13,14,15,16]
list_y = tnw_df2['oow']
plt.bar(list_x, list_y,
color='skyblue')
plt.xticks(list_x)
plt.yticks([0,20,50,80])
for i, v in enumerate(list_x): # 막대 바에 값 입력
plt.text(v, y[i], y[i], # 좌표 (x축 = v, y축 = y[0]..y[1], 표시 = y[0]..y[1])
fontsize = 9,
color='black',
horizontalalignment='center', # horizontalalignment (left, center, right)
verticalalignment='bottom') # verticalalignment (top, center, bottom)
plt.grid(False)- 컬럼을 그룹바이하면서 인덱스로 만들었는데 이걸 푸는 방법을 몰랐어서 직접 적었으나 인덱스를 풀면 컬럼으로 y입력이 가능해서 노가다 없이 편하게 할 수 있다..
- 인덱스 풀기: 데이터프레임명.reset_index()
1-2) 퍼블이 가장 많이 나오는 라인
더보기
가린 부분은 게임 아이디와 유저들 닉네임이다.
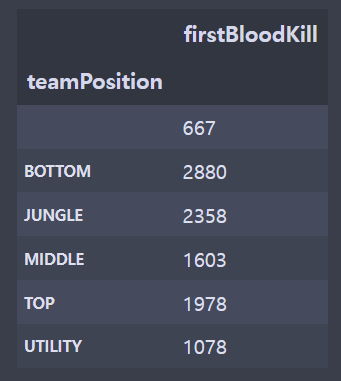
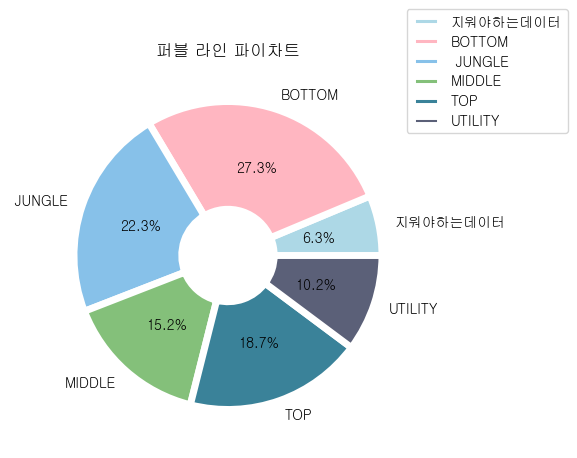
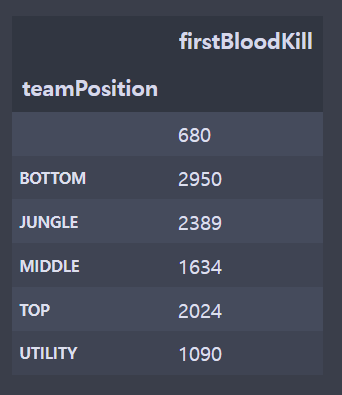
fbl = df[['gameId','championName','teamPosition','firstBloodKill']]
fbl['firstBloodKill'] = fbl.apply(lambda x: 1 if x.firstBloodKill=='True' else 0,axis=1)fblC = fbl[['teamPosition','firstBloodKill']].groupby(['teamPosition']).sum()plt.figure()
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 5}
plt.pie(fblC['firstBloodKill'], labels = ['지워야하는데이터','BOTTOM',' JUNGLE','MIDDLE','TOP','UTILITY'], autopct ='%1.1f%%',
explode = (0,0,0,0,0,0), colors = ['lightblue','lightpink','#87c1e9','#84c07a','#3a8299','#5b6078'], wedgeprops=wedgeprops)
plt.legend(loc='lower right', bbox_to_anchor=(1.4,0.8))
plt.title('퍼블 라인 파이차트')
plt.grid(True)- 전처리를 하지 않았기 때문에 지워야하는 빈 칸의 데이터가 존재했다. (라인이 존재하지 않는 게임)
2. 시각화 (충분하게 데이터를 가져오지 못했기 때문에 다이아 외엔 데이터가 적은 수로 진행했다.)
2-0) 시작 전
더보기





import my_utils as mu
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import seaborn as sns
from matplotlib.gridspec import GridSpec
import numpy as npfont_path = "C:/Windows/Fonts/gulim.ttc"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font) # 윈도우def dfc(tier):
query = f'select * from lol_datas where tier="{tier}"'
return pd.DataFrame(mu.sql_execute_dict(conn,query))conn = mu.connect_mysql()
tiers = ['BRONZE','SILVER','GOLD','PLATINUM','DIAMOND']
br = dfc('BRONZE')
si = dfc('SILVER')
go = dfc('GOLD')
pl = dfc('PLATINUM')
di = dfc('DIAMOND')
conn.close()- 가린 부분은 게임 아이디, 게임시간, 게임버전, 유저들 닉네임이다.
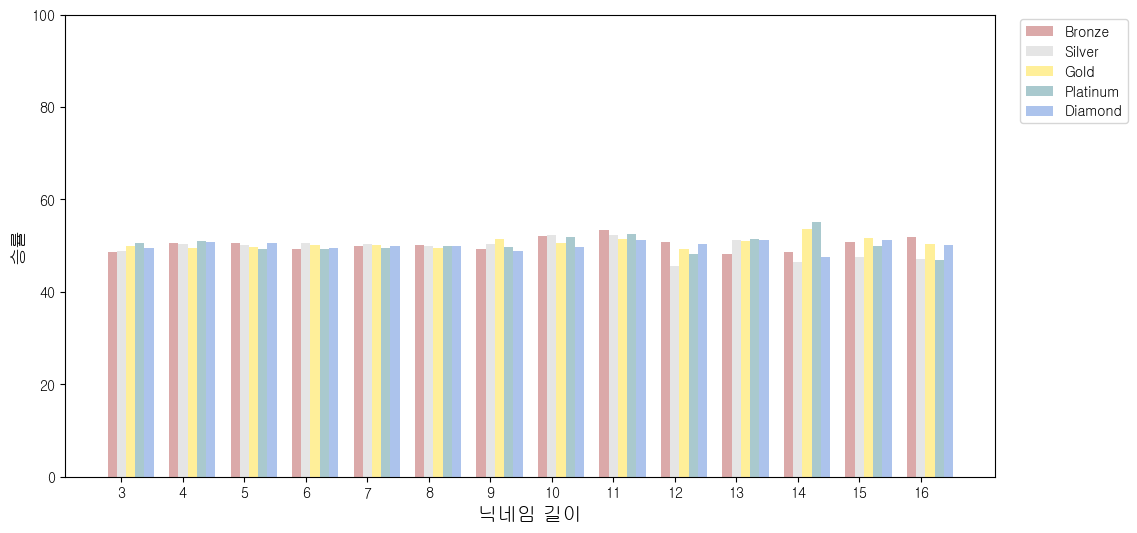
2-1) 닉네임 길이 별 승률
- for문으로 돌리려고 했는데 시행착오를 거쳤음에도 방법을 찾지 못했다..
더보기
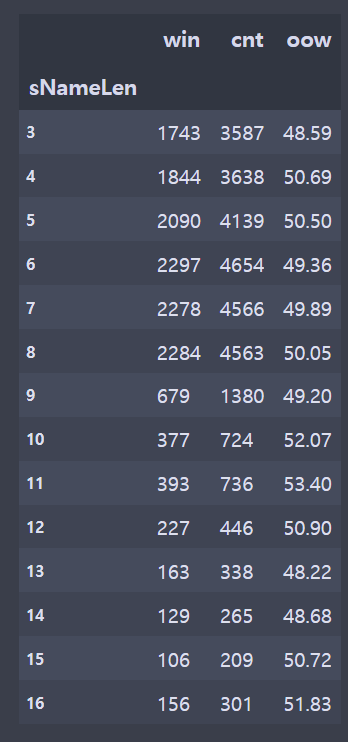
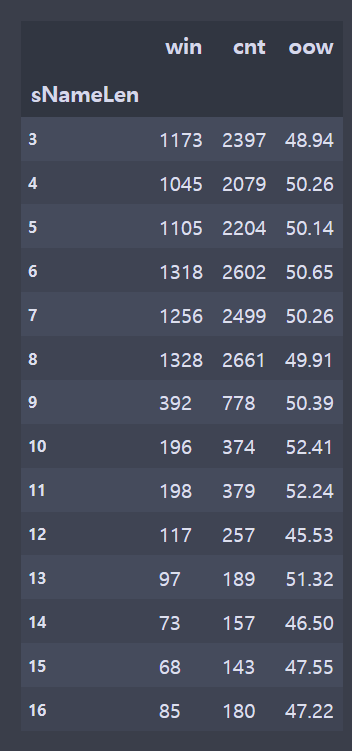
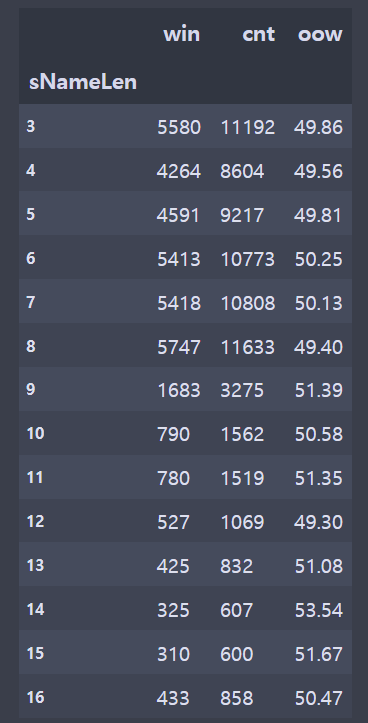
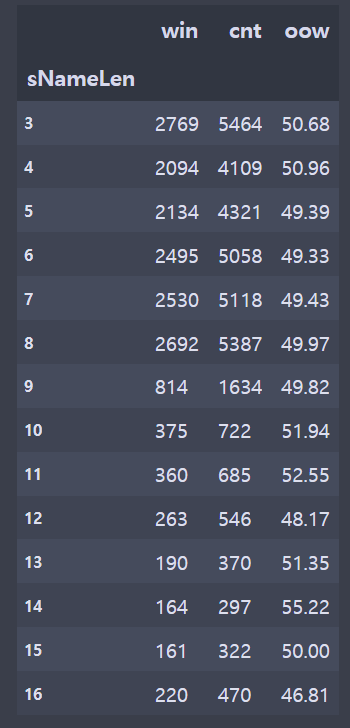
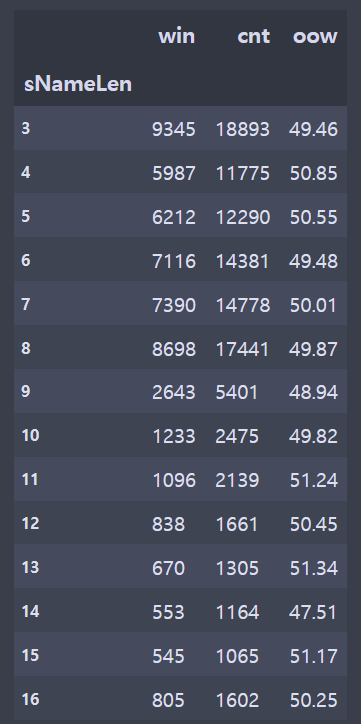
brDF = br[['tier','summonerName','win']]
brDF = pd.DataFrame(brDF[brDF.summonerName.str.len()!=0])
brDF['sNameLen'] = brDF['summonerName'].str.len()
brDF['cnt'] = 1
brDF = brDF[['tier','summonerName','sNameLen','win','cnt']]
brDF['win'] = brDF.apply(lambda x: 1 if x.win=='True' else 0,axis=1)
brDF = brDF[['sNameLen','win','cnt']].groupby(['sNameLen']).sum()
brDF['oow'] = round((brDF['win']/brDF['cnt'])*100,2)
siDF = si[['tier','summonerName','win']]
siDF = pd.DataFrame(siDF[siDF.summonerName.str.len()!=0])
siDF['sNameLen'] = siDF['summonerName'].str.len()
siDF['cnt'] = 1
siDF = siDF[['tier','summonerName','sNameLen','win','cnt']]
siDF['win'] = siDF.apply(lambda x: 1 if x.win=='True' else 0,axis=1)
siDF = siDF[['sNameLen','win','cnt']].groupby(['sNameLen']).sum()
siDF['oow'] = round((siDF['win']/siDF['cnt'])*100,2)
goDF = go[['tier','summonerName','win']]
goDF = pd.DataFrame(goDF[goDF.summonerName.str.len()!=0])
goDF['sNameLen'] = goDF['summonerName'].str.len()
goDF['cnt'] = 1
goDF = goDF[['tier','summonerName','sNameLen','win','cnt']]
goDF['win'] = goDF.apply(lambda x: 1 if x.win=='True' else 0,axis=1)
goDF = goDF[['sNameLen','win','cnt']].groupby(['sNameLen']).sum()
goDF['oow'] = round((goDF['win']/goDF['cnt'])*100,2)
plDF = pl[['tier','summonerName','win']]
plDF = pd.DataFrame(plDF[plDF.summonerName.str.len()!=0])
plDF['sNameLen'] = plDF['summonerName'].str.len()
plDF['cnt'] = 1
plDF = plDF[['tier','summonerName','sNameLen','win','cnt']]
plDF['win'] = plDF.apply(lambda x: 1 if x.win=='True' else 0,axis=1)
plDF = plDF[['sNameLen','win','cnt']].groupby(['sNameLen']).sum()
plDF['oow'] = round((plDF['win']/plDF['cnt'])*100,2)
diDF = di[['tier','summonerName','win']]
diDF = pd.DataFrame(diDF[diDF.summonerName.str.len()!=0])
diDF['sNameLen'] = diDF['summonerName'].str.len()
diDF['cnt'] = 1
diDF = diDF[['tier','summonerName','sNameLen','win','cnt']]
diDF['win'] = diDF.apply(lambda x: 1 if x.win=='True' else 0,axis=1)
diDF = diDF[['sNameLen','win','cnt']].groupby(['sNameLen']).sum()
diDF['oow'] = round((diDF['win']/diDF['cnt'])*100,2)name = [3,4,5,6,7,8,9,10,11,12,13,14,15,16]
# 그림 사이즈, 바 굵기 조정
fig, ax = plt.subplots(figsize=(12,6))
bar_width = 0.15
# 닉네임 길이 개수
index = np.arange(14)
# 바
b1 = plt.bar(index, brDF['oow'], bar_width, alpha=0.4, color='brown', label='Bronze')
b2 = plt.bar(index + bar_width, siDF['oow'], bar_width, alpha=0.4, color='silver', label='Silver')
b3 = plt.bar(index + 2 * bar_width, goDF['oow'], bar_width, alpha=0.4, color='Gold', label='Gold')
b4 = plt.bar(index + 3 * bar_width, plDF['oow'], bar_width, alpha=0.4, color='#287a86', label='Platinum')
b5 = plt.bar(index + 4 * bar_width, diDF['oow'], bar_width, alpha=0.4, color='#316bd1', label='Diamond')
plt.xticks(np.arange(bar_width, 14 + bar_width, 1), name)
plt.ylim(0,100)
# x축, y축 이름 및 범례 설정
plt.xlabel('닉네임 길이', size = 14)
plt.ylabel('승률', size = 13)
plt.legend(labels=['Bronze','Silver','Gold','Platinum','Diamond'], loc='lower right', bbox_to_anchor=(1.15,0.75))
plt.grid(False)- 바에 값을 적는건 어째서인지 자꾸 에러가 나서 지웠더니 에러가 사라졌다..ㅠㅠ
2-2) 퍼블이 가장 많이 나오는 라인
더보기
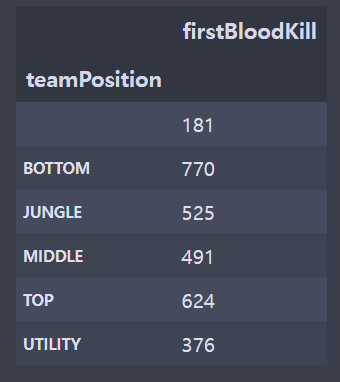
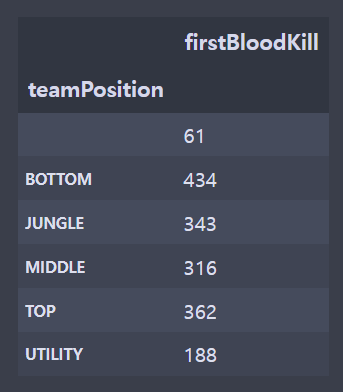
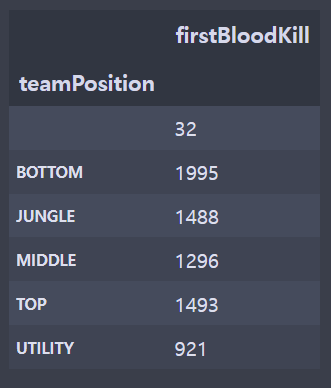
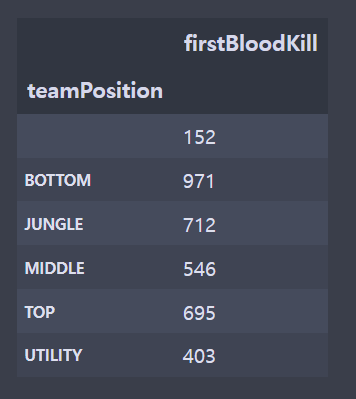
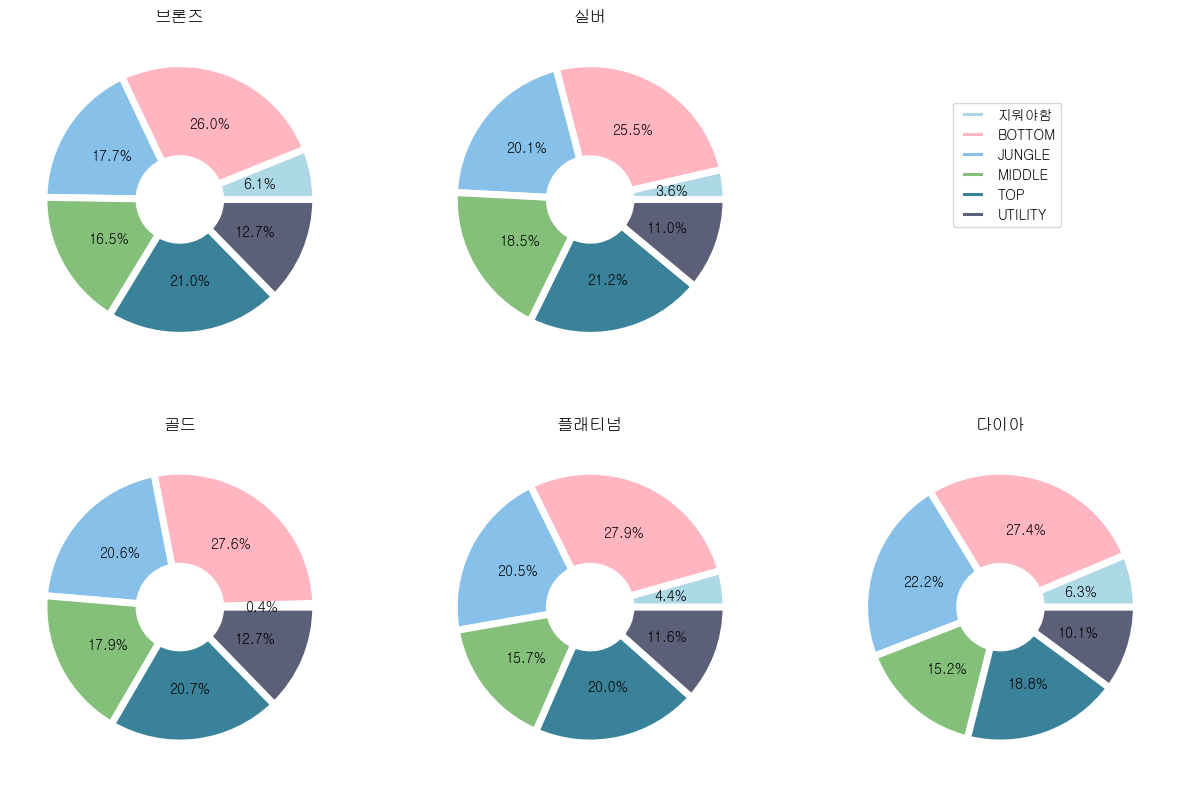
fbr = br[['gameId','championName','teamPosition','firstBloodKill']]
fbr['firstBloodKill'] = fbr.apply(lambda x: 1 if x.firstBloodKill=='True' else 0,axis=1)
fbr = fbr[['teamPosition','firstBloodKill']].groupby(['teamPosition']).sum()
fsi = si[['gameId','championName','teamPosition','firstBloodKill']]
fsi['firstBloodKill'] = fsi.apply(lambda x: 1 if x.firstBloodKill=='True' else 0,axis=1)
fsi = fsi[['teamPosition','firstBloodKill']].groupby(['teamPosition']).sum()
fgo = go[['gameId','championName','teamPosition','firstBloodKill']]
fgo['firstBloodKill'] = fgo.apply(lambda x: 1 if x.firstBloodKill=='True' else 0,axis=1)
fgo = fgo[['teamPosition','firstBloodKill']].groupby(['teamPosition']).sum()
fpl = pl[['gameId','championName','teamPosition','firstBloodKill']]
fpl['firstBloodKill'] = fpl.apply(lambda x: 1 if x.firstBloodKill=='True' else 0,axis=1)
fpl = fpl[['teamPosition','firstBloodKill']].groupby(['teamPosition']).sum()
fdi = di[['gameId','championName','teamPosition','firstBloodKill']]
fdi['firstBloodKill'] = fdi.apply(lambda x: 1 if x.firstBloodKill=='True' else 0,axis=1)
fdi = fdi[['teamPosition','firstBloodKill']].groupby(['teamPosition']).sum()# 그리드 스펙 설정
gs = GridSpec(3, 3)
# 이미지 사이즈 설정
fig = plt.figure(figsize=(15, 15))
# 크기와 위치가 다른 서브플롯 생성
ax1 = fig.add_subplot(gs[1, 0])
ax2 = fig.add_subplot(gs[1, 1])
ax3 = fig.add_subplot(gs[2, 0])
ax4 = fig.add_subplot(gs[2, 1])
ax5 = fig.add_subplot(gs[2, 2])
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 5} # 파이차트를 부채꼴로 만듦
ax1.pie(fbr['firstBloodKill'], autopct ='%1.1f%%',
explode = (0,0,0,0,0,0), colors = ['lightblue','lightpink','#87c1e9','#84c07a','#3a8299','#5b6078'], wedgeprops=wedgeprops)
ax2.pie(fsi['firstBloodKill'], autopct ='%1.1f%%',
explode = (0,0,0,0,0,0), colors = ['lightblue','lightpink','#87c1e9','#84c07a','#3a8299','#5b6078'], wedgeprops=wedgeprops)
ax3.pie(fgo['firstBloodKill'], autopct ='%1.1f%%',
explode = (0,0,0,0,0,0), colors = ['lightblue','lightpink','#87c1e9','#84c07a','#3a8299','#5b6078'], wedgeprops=wedgeprops)
ax4.pie(fpl['firstBloodKill'], autopct ='%1.1f%%',
explode = (0,0,0,0,0,0), colors = ['lightblue','lightpink','#87c1e9','#84c07a','#3a8299','#5b6078'], wedgeprops=wedgeprops)
ax5.pie(fdi['firstBloodKill'], autopct ='%1.1f%%',
explode = (0,0,0,0,0,0), colors = ['lightblue','lightpink','#87c1e9','#84c07a','#3a8299','#5b6078'], wedgeprops=wedgeprops)
ax1.set_title('브론즈')
ax2.set_title('실버')
ax3.set_title('골드')
ax4.set_title('플래티넘')
ax5.set_title('다이아')
plt.legend(labels=['지워야함','BOTTOM','JUNGLE','MIDDLE','TOP','UTILITY'], loc='lower right', bbox_to_anchor=(0.7,1.6))
plt.show()- 전처리를 하지 않았기 때문에 지워야하는 빈 칸의 데이터가 존재했다. (라인이 존재하지 않는 게임)
참고한 글 링크 목록
- (그래프)바에 값 표시
- 파이차트 부채꼴 스타일
- 한 번에(한 이미지에) 차트 여러개 띄우기 (한 줄에 여러개 쓰면 뜨긴 하는데 이건 따로따로 띄우는거라 쓸모가 없다.)
- 라벨 없애기
- y축 범위 설정
728x90
'프로그래밍 > +a' 카테고리의 다른 글
| slPro 5차 일지 (0) | 2024.01.09 |
|---|---|
| slPro 4차 일지 (1) | 2024.01.08 |
| slPro 3차 일지 (0) | 2024.01.01 |
| 미니 팀 프로젝트 사전 준비 (파이썬) (2) | 2024.01.01 |
| slPro 2차 일지 (0) | 2023.12.28 |